前言
暑假在看c++面经时,看到了腾讯的一道面试题。
题目大意是:求(2^1e10)%10000的值,限制了时间复杂度。
在C++中没有Java和Python中的大数,不知道读者朋友们可否AC此题。
正文
这道题可以用快速幂来AC。
请听我详细道来。
在学习了二进制相关知识后,我们知道任何一个数都可以用唯一的二进制表示,也就是说每一个数可以唯一表示为若干指数不重复的2的次幂的和。
举个例子:假设b在二进制表示下有k位。则b可以表示为:
b=ck-12^k-1^+ck-22^k-2^+ck-32^k-3^+……+c12^1^+c02^0^
快速幂常见的模式为:
- 给定a,b,p的值,求(a^b)%p的值。a,b,p都是大数,1<= a ,b ,p<=1e10.
- 给定a,b,p的值,求(a*b)%p的值。a,b,p都是大数,1<= a ,b ,p<=1e10.
1. (a^b)%p
有上面的例子可知:
b=ck-12^k-1^+ck-22^k-2^+ck-32^k-3^+……+c12^1^+c02^0^
则 a^b= a^ck-12k-1^+a^ck-22k-2^+a^ck-32k-3^+……+a^c121^+a^c020^
由于数学格式支持的不是很好,贴一个图说明一下。
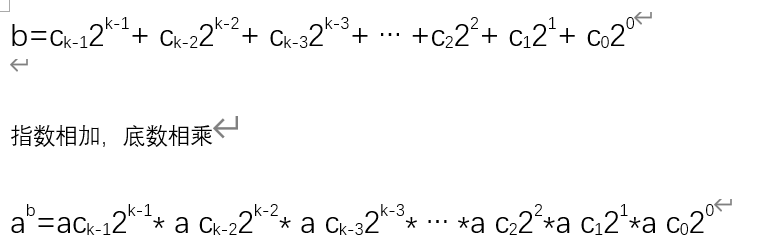
算法分析:
根据上式我们发现,原问题被我们转化成了形式相同的子问题的乘积,并且我们可以在常数时间内从2^k-1^项推出 2^k^项。
这个算法的复杂度是O(logN) 的,我们计算了logN个 2^K^次幂的数,然后花费 logN 的时间选择二进制为 1 对应的幂来相乘。
来个题目练练手 :计算 (a^b)%p的值
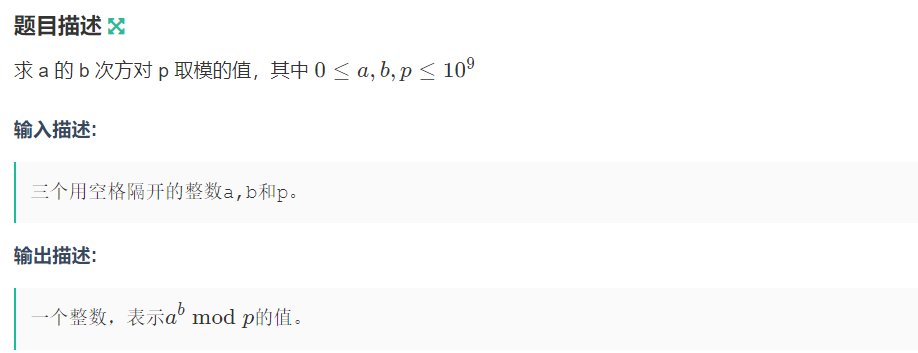
1 |
|
2.(a*b)%p
同第一张模板类似,同理:
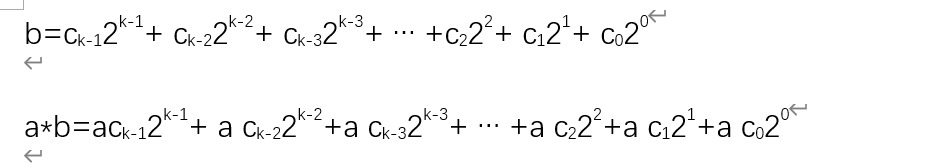
来道题练练手:求(a*b)%p

1 | #include<iostream> |
注意事项
由于快速幂的数据很大,在使用c++做题时,用单纯的cin来输入测试用例很慢,会导致超时。
在这里给两个小建议:
- cin前面加上这条取消同步的语句
1 | cin.tie(nullptr)->sync_with_stdio(false); |
- 用scanf()来读取。
最后
关于快速幂的题型还有很多,比如快速幂矩阵,计算斐波那契数等。
这篇文章所讲的只是快速幂的初阶内容,我在后面会为大家分享更高阶的快速幂知识。
好啦,就先到这里了。我们下期再见!